What is synthetic biology?
Synthetic biology involves designing biological systems to a desired performance specification — for example, designing a cell to produce x grams of a renewable biofuel, or a biomaterial that can withstand the pressure of y tons per square inch. This can be done by modifying an organism’s genetic code. As genetic engineering has become more powerful and easier to perform, it has evolved into synthetic biology, and has allowed scientists to make a wide variety of products, from cosmetics and renewable bio-based fuels to meatless burgers and synthetic silk. Synthetic biology has the potential to revolutionize how everyday products are made in the future.
However, the processes that take place within synthetic biology are not very predictable. For example, it’s difficult for scientists to accurately predict how genetic engineering will affect a cell’s behavior. It’s also difficult to predict how a small experiment done in a lab will perform when it’s scaled up to larger amounts.
“Predicting anything in biology is, in general, difficult,” said Héctor García Martín, a researcher at Lawrence Berkeley National Laboratory (Berkeley Lab). “We’re spoiled in other disciplines such as physics, where we can put centuries of knowledge into mathematical models that are able to make predictions quite well. But DNA was only discovered in the 1950s, so we’ve only been engineering biology by manipulating DNA for 70 years.”
Scientists have mostly relied on empirical approaches to find out what works and what doesn’t. As a result, making things with synthetic biology has taken a long time. For example, it took 150 person years to make artemisinin, an anti-malarial drug. The ability to make groundbreaking achievements through synthetic biology is limited unless it becomes more predictable, said García Martín.
In recent years, scientists have begun to explore how machine learning’s predictive power could solve this challenge.
What is machine learning and how can it be applied to synthetic biology efforts?
Machine learning is part of the broader field of artificial intelligence (AI), an area of study that seeks to mimic how the human brain works and use this ability to solve a variety of problems.
Specifically, machine learning involves the study and creation of algorithms that improve their performance automatically by learning from significant amounts of high quality training data. For example, scientists can teach an algorithm to recognize dogs in images by training them with a database of example dog pictures.
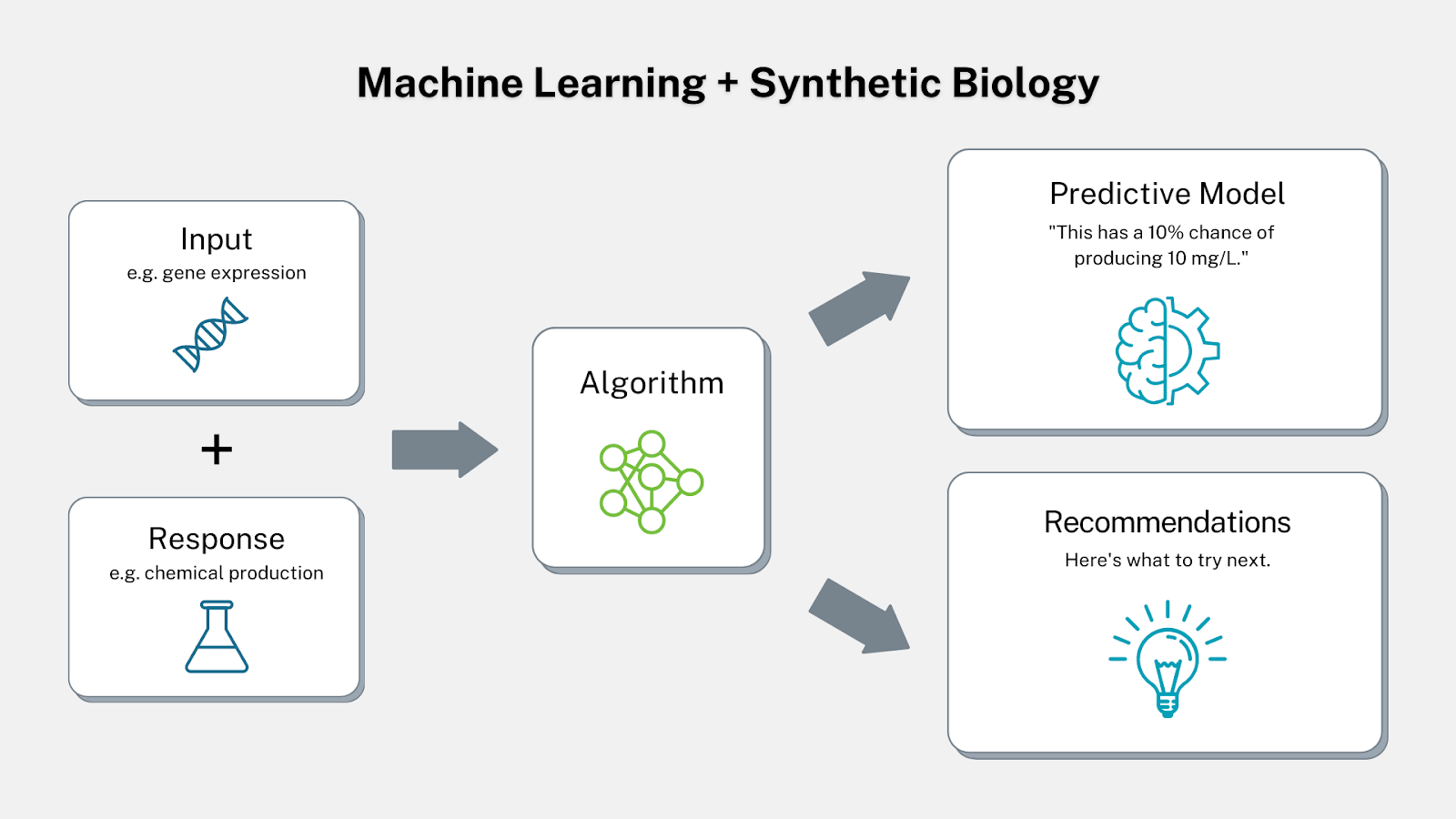
In the case of synthetic biology, machine learning can predict how engineering a biological system will affect its behavior. It can then provide recommendations for what researchers should try next.
This is done by mapping an input (such as protein expression patterns) to the desired response (such as production of a biofuel). An algorithm can “train” on this information and recommend what needs to be done to achieve the desired response.
García Martín and his team developed the Automated Recommendation Tool (ART) algorithm to work in this fashion for synthetic biology purposes. The algorithm can guide scientists’ efforts by training on datasets and recommending which strains to develop in the next engineering cycle. It also predicts what production levels these strains will be able to produce.
Given the complexity of cells and the fact that synthetic biology is still a relatively young field, machine learning allows researchers to do this work without requiring a deep understanding of the biochemical pathways they’re working with. This is similar to the way social media platforms can predict your likes and dislikes without ever talking to you.
This makes synthetic biology more accessible and efficient, said García Martín. “Right now, using standard approaches, it’s impossible to predict many of these things,” he said. “Machine learning not only makes it possible, it also makes it fast.”
What’s an example of how machine learning can improve synthetic biology?
Scientists at the Novo Nordisk Foundation Center for Biosustainability at the Technical University of Denmark used the ART algorithm to systematically guide the production of tryptophan, a food additive and precursor to vitamin B3.
The researchers identified five genes in the biochemical pathway that have significant impact in producing tryptophan; however, it wasn’t clear what combination of gene expression would maximize tryptophan production — there were over 8,000 possible combinations of gene promoters to sort through. So the researchers created a random sample of around 300 of the possible gene promoter combinations and used this data set to “train” the ART algorithm and find the best option among all the combinations.
In this case, by providing the algorithm with the input (the possible combinations of gene promoters/expression) and the desired output (production of tryptophan), the algorithm was able to sort through the options and recommend which combination would improve tryptophan production. Instead of trying each of the combinations one by one, this method quickly provided researchers with a clear best course of action.
Similar approaches are now routinely used at the Joint BioEnergy Institute (JBEI) to produce renewable biofuels, and at the Agile Biofoundry (ABF) to accelerate synthetic biology.
What needs to be done to increase adoption of machine learning for synthetic biology efforts?
Machine learning requires large amounts of high-quality data to train algorithms. The main challenge in synthetic biology is acquiring this data.
“There needs to be a change of thinking, from the single metabolic engineer working in an ad-hoc way, in which a single person takes a cell, looks at the literature, decides which pathway to use, and so on,” García Martín said. “Instead, synthetic biology needs to shift to a team-science, pipeline approach that produces a stream of data in a systematic way.”
García Martín and his teams at JBEI and ABF are working to create “self-driving” labs that acquire data in a systematic fashion, and use AIs to ingest these data and decide the next set of experiments. This would involve automated robotic platforms that take measurements while doing experiments, providing large amounts of data that can then be input into algorithms. These algorithms would autonomously decide which experiments to do next and which scientific hypotheses to test.
Putting this data to use will require interdisciplinary collaborations between metabolic engineers, synthetic biologists, automation experts, mathematicians and machine learning experts, said García Martín.
“The national laboratories have the capability to do this approach,” he said. “For example, a team could provide the cells, another team would design algorithms to decide the target chemical to synthesize, another team would provide the technology to test and measure the system’s performance in a high-throughput fashion, and a final team would provide the algorithms to control the automated experiments in a productive way. This is the national labs approach, and it will really help advance the field.”
Using machine learning to guide synthetic biology research could speed up the development of new technologies and help us better understand the underlying processes of biological systems. A future where these two fields intersect could result in a disruptive change.
“It would be a future where you could create cells to specification very easily,” García Martín said. “And that could be done to create everything from biofuels to biomaterials to medicine.”
As climate change accelerates, synthetic biology enhanced by machine learning and automation could provide disruptive capabilities that would allow bioengineering to make a difference in the worldwide struggle to halt or even reverse climate change.
What does a day in the life of a researcher in this field look like?
Tijana Radivojevic, a data scientist at Berkeley Lab with a background in applied mathematics, works in García Martín’s Qualitative Metabolic Modeling Group. She came into this field with no formal background in biology or chemistry.
“As a postdoctoral researcher, I started working on creating algorithms for the needs of synthetic biology and became fascinated with the field,” Radivojevic said.
On any given day, Radivojevic could be brainstorming with colleagues on how to design experiments or what scientific questions to ask, creating pipelines for data generation, or developing algorithms or software tools.
“No day is the same, and that’s the beauty of my work,” she said.
Radivojevic said she particularly enjoys collaborating with scientists from various backgrounds.
“The most rewarding part is when we realize our joint efforts have guided us in the right direction — for example, when we’re able to achieve increased production of a target molecule,” she said.
Being exposed to different mindsets and scientific approaches has allowed her to develop skills that she can apply to all aspects of her career, she added.
“This field is very rewarding, as we’re dealing with critical issues that society is facing,” Radivojevic said. “Synthetic biology enabled by machine learning has so many applications. We have the opportunity to sustainably create materials that have specific properties, but there is also a potential to make materials that have improved features over what is already present in nature.”
Radivojevic encourages scientists with a computational background who may be interested in this work to explore how they can contribute to this field. “Not only can their contributions be very valuable, but there is also a lot they can gain as scientists from being exposed to these multidisciplinary approaches.”